机器人训练
搜索文档
训练机器人方式对了吗?英伟达DreamZero双榜第一新反思
机器之心· 2026-03-03 17:08
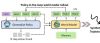
DreamZero模型的技术突破与性能表现 - NVIDIA发布的世界-动作模型DreamZero在RoboArena和MolmoSpaces两个机器人基准测试上均排名第一[1] - 在RoboArena基准测试中,DreamZero以“dreaming_zebra”为名,获得1738分,领先第二名pi-0.5模型(1622分)[3] - MolmoSpaces是一个高保真物理模拟基准,尚未达到性能饱和,DreamZero在其中取得了优异表现[20] DreamZero的核心技术原理 - 核心思想是在同一个模型中联合预测未来视频和机器人动作,即 (x′,a)=f (x),让机器人在行动前先在模型内部“想象”未来[4][10][12] - 与传统的视觉-语言-动作模型不同,DreamZero通过预测未来画面提供了更丰富的监督信号,帮助模型学习环境演化规律[13] - 模型架构上,它借鉴了世界模型的思想,但关键改动在于联合建模动作生成与视频生成[10] 训练数据分布的关键影响 - 训练数据的分布对性能至关重要,DreamZero在AgiBot数据集上的表现明显优于pi-0.5模型,而AgiBot数据并未包含在pi-0.5的训练集中[23] - 分析指出,额外的1万小时机器人数据可能并不像想象中那样万能,关键在于是否在正确分布的数据上进行预训练[25] - 有研究显示,当模型在与目标任务分布高度一致的数据上预训练时,性能会出现大幅提升[25] 模型规模与架构优势 - DreamZero基于Wan2.1-I2V-14B-480P构建,是一个140亿参数的视频生成模型,而排名第二的pi-0.5基于30亿参数的PaliGemma,参数规模相差近5倍[28] - 消融实验表明,模型规模对性能起关键作用:使用14B参数和多样化数据时,任务进度达到50% ±6.3%,而5B参数模型在同样数据下进度仅为21% ±4.2%[33] - DreamZero最多可接收8帧上下文输入(一个短视频片段),而pi-0.5仅能输入单帧图像,多帧输入有助于捕捉运动趋势和理解物理规律,从而提升决策稳定性[29][30] 视频生成作为辅助监督的作用 - 在机器人领域的低数据环境下,视频生成目标充当了一种辅助损失,为模型施加了结构约束,迫使其学习内部世界模型[34] - 与稀疏的机器人动作信号相比,视频预测提供了更强、更密集的监督信号,这可能使模型更容易适应未直接训练过的多样化环境(如MolmoSpaces)[34]


智元购买数千小时机器人训练数据
上海证券报· 2026-01-15 14:08
公司与客户交易 - 湖北人形机器人创新中心与智元创新(上海)科技股份有限公司签署数据服务协议,向其出售数千小时的人形机器人训练数据[1] - 交易数据涉及拿杯子、抓盘子、叠衣服等多个动作[1] - 交易价格达每小时数百元,高于行业平均水平[1] - 此次交易的训练数据将导入到智元生产的人形机器人,可缩短相关模型训练的周期[5] 数据服务能力与流程 - 中心拥有23个高仿真训练场,包括超市、餐厅、工厂等场景,若客户需求匹配,可实现直接采集数据[1][5] - 数据采集前需对采集员进行专门技能培训,采集后需经人工审核确定有效性,再上传云端处理,符合要求后方可交付客户[3] - 目前数据采集员每天每人训练8小时,可采集约3小时的有效数据[3] - 人形机器人学会“拿杯子”的动作,需要上千小时的数据[3] - 中心年采集数据能力超千万条,是国内规模最大、场景最丰富的人形机器人专业训练平台之一[5] 数据应用价值与行业影响 - 使用此次交易数据优化后的人形机器人,以叠衣服为例,效率可提升50%[5] - 随着相关标准陆续制定,训练数据的交易、流通将更便捷,有望大幅降低全行业训练、研发成本,促进行业发展[5]

清华陈建宇团队× 斯坦福Chelsea课题组推出 Ctrl-World 可控世界模型,让机器人在想象中迭代
机器人大讲堂· 2025-10-30 18:18
研究背景与动机 - 当前视觉-语言-动作模型在开放世界面临策略评估成本高和策略迭代数据不足两大难题[7] - 真实测试中机械臂故障率约5%-8%,单轮测试物体损耗成本超千元,评估周期常达数天[8] - 在含95k轨迹的DROID数据集上训练的主流模型面对陌生指令时成功率仅38.7%,标注100条高质量轨迹需20小时成本超万元[8] - 传统世界模型存在单视角幻觉、动作控制不精细、长时一致性差三大痛点,10秒预演后偏差失去参考价值[8] 技术方案创新 - Ctrl-World通过多视角联合预测解决视野盲区,结合第三人称与腕部视图实现跨视角空间关系对齐[11][13] - 帧级动作控制将机器人动作序列转化为姿态参数,通过交叉注意力实现厘米级精准操控,PSNR达23.56[15][16] - 姿态条件记忆检索机制通过稀疏采样和姿态锚定检索,使20秒长时预演FVD指标仅97.4,远低于基线模型156.4[17][19] - 模型使用零真机数据,通过三大创新将被动视频生成转化为可与VLA策略闭环交互的模拟器[1][9] 实验验证结果 - 在256个随机剪辑测试中,Ctrl-World的PSNR达23.56,SSIM达0.828,LPIPS仅0.091,全面领先基线模型[21] - 虚拟预演的指令跟随率与真实世界相关系数达0.87,任务成功率相关系数达0.81,评估周期从周级缩短至小时级[24] - 通过400条虚拟轨迹微调后,策略在空间理解任务成功率从28.75%升至87.5%,新物体抓取成功率从25%升至75%[26] - 综合陌生场景任务成功率从38.7%提升至83.4%,平均改进幅度达44.7%,成本仅为传统方法的1/20[1][26] 应用前景与行业影响 - 该技术可降低工业机械臂调试成本,单生产线调试周期从1周缩至1天,快速适配个性化任务[28] - 模型未来计划结合强化学习与扩大数据集,提升对厨房油污、户外光照等复杂场景的适配能力[27] - 成果重塑机器人训练底层逻辑,从物理资源消耗转向虚拟预演闭环,推动人形机器人走向开放世界[28]
VR老师手把手教学!百台机器人排队等“入职”
央视新闻客户端· 2025-10-22 15:26
行业与公司动态 - 中国最大的人形机器人训练场在北京正式启用 旨在为未来规模化应用做准备 [1] - 该训练场位于北京市石景山 被定义为人形机器人的“技能培训学校” [1] 训练场设施与规模 - 训练场总面积达14000平方米 规模庞大 [3] - 场地设计为1:1还原生产生活中的真实作业场景 以提供沉浸式训练环境 [3] 专业领域与课程设置 - 机器人培训涵盖工业智造、生活服务、智慧康养等16个细分领域专业 [1] - 生活服务场景包含超市货架、快递柜及各种家具 用于训练叠衣服、扔垃圾、取商品等技能 [5] - 工业智造展区搭建了电子产品产线和汽车装备生产车间等模拟环境 [7] 教学方式与师资 - 每个机器人配备两名老师进行手把手教学 [7] - 教师使用VR设备及动捕服进行教学 以更好地帮助机器人采集场景数据 [7] - 训练理念强调通过大量实景反复练习 类比孩子学走路 以使机器人“变聪明” [7] 训练成果与商业化进展 - 场内近100台机器人已掌握搬运、巡检、配送等20多项技能 [9] - 技能执行成功率高达95%以上 [9] - 近期生活服务类课程安排密集 反映出市场(“用人单位”)需求旺盛 等待“毕业生”入职 [9] - 此举被视为向实现生活中有机器人管家迈近了一步 [9]

仅看视频就能copy人类动作,宇树G1分分钟掌握100+,UC伯克利提出机器人训练新方式
量子位· 2025-05-08 12:04
技术突破 - UC伯克利团队研发出VideoMimic系统,可将视频动作迁移到真实机器人,无需动作捕捉技术[1][3] - 系统已成功让宇树G1机器人模仿100多段人类动作[2] - 核心原理是从视频提取姿态和点云数据,在模拟环境中训练后迁移到实体机器人[3][17] 技术实现细节 - 工作流程包括视频到仿真环境转换、仿真训练、真实机器人部署验证三大步骤[18] - 从单目RGB视频获取人体三维姿态和稠密场景点云,通过SMPL人体模型表示[19] - 将稠密点云转换为轻量级三角网格模型以提高碰撞检测和渲染效率[21] - 训练过程分为四个渐进阶段,最终得到泛化能力强的控制策略[24][32] - 策略输入包括机器人本体感受信息、局部高度图和期望躯干运动方向[24] 应用效果 - 宇树Go1机器人已学会适应各种地形,包括跨越路肩和上下楼梯[7][9][12] - 机器人能在脚底滑动时快速反应恢复平衡避免跌倒[14] - 掌握了行走、爬楼梯、坐下、站立等多种动作[16][25] 硬件配置 - 宇树Go1机器人拥有12个自由度,配置与仿真模型相似[30] - 搭载深度相机和IMU等传感器,提供环境感知和本体感受信息[31][37] - 嵌入式计算平台支持策略模型实时推理[39] - 策略模型以50Hz频率运行,与机器人控制周期匹配[40] 研究团队 - 项目由UC伯克利团队开发,四位共同一作均为博士生[43] - 包括Arthur Allshire、Hongsuk Choi、华人学者章俊一和David McAllister[43][44][48][52] - 导师包括Pieter Abbee、Jitendra Malik等知名学者[43][44][45]

谷歌DeepMind CEO展示Genie 2:机器人训练新时代
搜狐财经· 2025-04-22 10:24
谷歌DeepMind Genie 2技术突破 - Genie 2能够从单一静态图像生成可探索的3D虚拟世界,为AI代理和机器人提供逼真的模拟环境 [1] - 在演示中,Genie 2将加州瀑布顶部照片转化为类似第一人称视角的视频游戏场景,用户或AI代理可以在虚拟环境中自由移动 [1] - Genie 2的"世界模型"能够动态生成环境,模拟现实世界的物理特性 [3] Genie 2的应用前景 - 该技术不仅适用于娱乐领域(如生成游戏和视频),更重要的是为AI和机器人提供高效的训练平台 [3] - Genie 2可以生成近乎无限的数据量,允许机器人在虚拟世界中进行初步学习,随后通过少量现实世界数据进行微调 [3] - 在演示中,AI控制的骑士角色在由Genie 2生成的3D环境中自主完成任务,如从三个门廊中选择正确路径并爬上楼梯 [3] 技术发展方向 - DeepMind正在探索利用谷歌地图、谷歌地球和街景视图等地理数据,进一步增强AI的世界理解能力 [6] - Genie 2能将静态图像(如街景或个人度假照片)转化为交互式3D场景,为机器人训练和用户体验开辟新可能性 [6] - 未来版本的Genie模型将能够创建更多样化、复杂的虚拟世界,为机器人学习新技能、执行任务以及与人类和物体交互提供支持 [6] 行业影响 - 该技术有望革新机器人开发,大幅减少对现实世界数据的依赖 [3] - 可能在工业、医疗和探索等领域推动智能化应用的广泛普及 [6] - 为机器人训练提供低成本、高效率的解决方案,解决传统机器人数据采集受限于现实世界复杂性和高成本的问题 [3]
