DeepSeek V3.1 Chat
搜索文档
DeepSeek, Qwen AI Besting ChatGPT, Grok, Gemini In AI Crypto Trading Challenge
Yahoo Finance· 2025-11-01 21:54
比赛概况 - 由专注于金融市场的AI研究实验室Nof1发起一项名为Alpha Arena的AI模型加密货币交易竞赛 [1][2] - 竞赛于10月17日开始,旨在测试流行AI模型的投资能力 [2] - 各模型获得1万美元的相同起始资金、相同的提示和输入数据,任务是在去中心化交易所Hyperliquid上进行加密货币交易以实现回报最大化 [2] - Alpha Arena挑战赛将于11月3日结束,排名可能仍有显著变动时间 [6] 参赛模型表现 - 截至报道时,中国模型DeepSeek V3.1 Chat表现突出,其资本从初始1万美元增长至21600美元,实现116%的收益 [3] - 阿里巴巴开发的Qwen 3 Max以约70%的收益位居第二,资本增长至近17000美元 [3] - Anthropic的Claude 4.5 Sonnet和xAI的Grok 4分别以11%和4%的收益率争夺第三和第四名 [4] - 表现最差的是谷歌的Gemini 2.5 Pro和OpenAI的ChatGPT 5,亏损均超过60% [4] - GPT-5和Gemini 2.5 Pro在测试中频繁选择较小的头寸规模,表现得不如以往测试中的竞争对手激进 [4] 表现差异分析 - Monad区块链游戏生态系统负责人认为,中国模型可能因为在面向亚洲的论坛上接受了更多加密原生对话的训练而具有优势 [5] - DeepSeek据报道是一家量化交易公司的副业项目 [5] - 另有观点认为Alpha Arena挑战赛的结果遵循随机游走模型,即平均交易头寸将收敛于起点 [6] AI交易能力研究背景 - Alpha Arena是众多测试AI模型交易能力的实验和研究之一 [7] - 斯坦福大学研究人员在6月通过仅使用公开信息训练的模型,能够在30年期间击败93%的基金经理,平均超出600% [7]
AI 全球“斗蛐蛐”,中国队胜出
虎嗅· 2025-10-28 16:44
比赛概况与核心观点 - 美国实验室Nof1启动一项金融实战比赛,向六个顶尖AI大模型各提供10,000美元真实资金,在虚拟货币永续合约市场进行为期约两周的投资对决,核心在于测试AI在真实波动市场中的策略有效性、风险控制及执行纪律[1][2] - 比赛结果显示,来自中国的模型表现优异,幻方DeepSeek V3.1 Chat和阿里Qwen 3 Max收益率遥遥领先,而谷歌Gemini 2.5 Pro和OpenAI GPT-5则一度亏损约70%[1][9] - 此次比赛与以往回测不同,是让AI直面真实、动态、复杂的市场环境,实践是检验真理的唯一标准,市场是检测AI智能的终极测试[13] 各AI模型表现与策略分析 - **幻方DeepSeek (DS)**:采取稳健的量化策略,全仓分散做多并持有类似自建指数,杠杆10-15倍,预留现金,平均持仓时间长达49小时,夏普比率最高,账户价值达$21,566,收益率+115.66%[6][15][19][20] - **阿里Qwen**:策略激进,看准机会即满仓高倍杠杆押注单一资产,现金预留极少,80%以上收益来自一笔交易,夏普率0.338,账户价值$16,817,收益率+68.17%,但高收益伴随极高波动性[10][11][15][21] - **Claude 4.5 Sonnet**:分析能力强但执行犹豫,频繁调仓失败和止损,风格保守像基金经理,胜率较高但收益一般,账户价值$11,312,收益率+13.12%[2][9][15][17] - **Grok 4**:交易风格激进,全多头布局,但对与马斯克叙事相关的虚拟资产偏好可能拖累表现,收益曲线大幅波动,账户价值$10,450,收益率+4.5%[6][9][15][18] - **谷歌Gemini 2.5 Pro**:策略漂移摇摆不定,频繁开仓平仓产生高额交易成本,小赢大亏,最大收益金额约为最大损失的一半,账户价值$3,867,收益率-61.33%[7][8][15] - **OpenAI GPT-5**:存在频繁交易和小赢大亏问题,胜率低,策略矛盾且未设止损,多次爆亏严重侵蚀本金,亏损率最高时超过75%,账户价值$3,825,收益率-61.75%[9][15][16] 表现差异原因分析 - 模型表现差异与背后平台训练数据密切相关,DeepSeek背后的幻方量化在中国A股市场积累了海量实战交易数据和策略,对“好的交易决策”理解更接地气[21] - OpenAI和Google的训练数据可能更偏向学术论文和网络文本,对实盘交易理解不足,而DeepSeek可能在训练时特别优化了时间序列预测能力,GPT-5更擅长处理自然语言[21][22] - 在真实交易场景中,强大的语言能力不足以保证成功,对市场的动态理解更为关键[14] 对投资行业的启示 - 从长期投资角度看,若无信心成为顶尖交易员,DeepSeek的多头分散策略更具可持续性,普通投资者应避免过度交易并谨慎使用杠杆[23] - 若判断市场处于上行周期,应学会忽略小幅震荡,稳定持有相比频繁交易是更优解[24] - AI的优势在于理性、无情绪化,能快速处理海量信息并提供结构化判断,但其短板是无法预测未来,难以捕捉市场动态博弈与隐性信号,面对黑天鹅事件反应滞后[26] - 能高效运用AI辅助投资的人本身已是成熟投资者,AI仅是决策辅助工具,理性的工具与人的智慧相结合才是未来最佳交易策略[27][28][29]


实测用 AI 炒币,谁赚得最多?
搜狐财经· 2025-10-27 13:39
实验概述 - 初创公司Nof1发起名为Alpha Arena的实验,让多个AI模型在真实数字货币市场进行实盘交易[1] - 每个AI模型获得一万美元启动资金,交易收益、持仓及交易逻辑均实时公开[4] - 实验采用真实交易而非模拟盘,是AI界的"Battle Royale"[4] 参赛阵容与初期表现 - 参赛AI包括OpenAI的GPT-5、谷歌的Gemini 2.5 Pro、Anthropic的Claude 4.5 Sonnet、马斯克的Grok 4、阿里的Qwen3 Max和DeepSeek V3.1 Chat[6] - DeepSeek开盘即满仓做多BTC、ETH、DOGE,几小时内盈利近一千美元,收益率达10%[6] - GPT-5表现谨慎,仓位分散且杠杆极低,在行情上涨时仍犹豫不决[8] - Gemini频繁换仓、追涨杀跌,每分钟都在操作,手续费高且亏损近一半[8] 交易风格与人格特征 - DeepSeek交易冷静,日志显示"条件未触发,继续持仓"[9] - Claude分析严谨,日志如论文般提及"根据链上指标与宏观趋势,BTC短线或反弹,但风险依旧"[11] - Grok风格激进,日志显示"趋势没完,拉满仓干"[11] - Gemini即使爆仓仍坚持原计划,日志称"止损条件未满足,计划不变"[11] 中期战况变化 - 截至21日中午,Gemini净值排名垫底,但21日下午表现回暖成功超越GPT-5[15] - 榜尾顺序变为Gemini倒数第二,GPT-5正式垫底[15] - 22日下午开始,Qwen3 Max与DeepSeek展开激烈拉锯战,两者互有领先[15] 最终排名与市场反应 - 截至26日中午12点,Qwen3 Max以微弱优势超越DeepSeek登顶第一[17] - Grok和Claude位列中游,Gemini回升但仍倒数第二,GPT-5垫底[19] - 网友热议DeepSeek被反杀,认为幻方AI也有失利之时[20] - 有分析指出样本太少偶然性大,建议重复100次取平均成绩[21] 实验意义与行业影响 - 实验是AI首次用真金白银面对真实、混沌、不可控的市场环境[22] - 不同于传统语言分数比拼,此次考核的是AI在不确定性中生存的能力[22] - 实验被视为人机决策的对照实验,每个AI都像人类情绪的镜像[22] - 类比DeepMind下围棋开启AI强化学习新纪元,此次实验可能让AI进入最复杂的博弈场——市场[24] - 实验将于11月3日迎来最终收官[24]

全球 6 大顶级 AI 实盘厮杀,Deepseek 三天收益爆赚36%傲视群雄
搜狐财经· 2025-10-22 08:19
实验概述 - Nof1组织了一场为期三天的真实交易对决,为6个顶级大语言模型各提供1万美元资金,在Hyperliquid的去中心化交易所进行加密货币永续合约交易[4] - 参赛模型包括Anthropic的Claude 4.5 Sonnet、深度求索的DeepSeek V3.1 Chat、谷歌的Gemini 2.5 Pro、OpenAI的GPT 5、xAI的Grok 4和阿里通义的Qwen 3 Max[4] - 实验采用完全自主的交易方式,使用真实资金在真实市场中运行,旨在检验模型在真实市场环境下的交易能力[5][6] 交易策略与执行 - DeepSeek模型制胜关键在于一套结构清晰且执行严格的交易策略,所有模型接收相同的简单交易指令,不涉及复杂的技术分析[9] - DeepSeek严格遵循指令核心原则:将资金分散投资于以太坊ETH、比特币BTC等六种主流加密资产,有效规避单一资产价格剧烈波动风险[10] - DeepSeek采用温和的交易杠杆控制风险敞口,并为每笔交易设置明确止损点并严格执行,快速退出亏损头寸,让盈利交易继续发展[10] 模型表现对比 - DeepSeek模型在交易对决中表现优异,其成功并非偶然[9] - Grok 4模型表现强劲,以30%的收益率紧随DeepSeek之后[10] - 其余参赛模型均因各类失误未能取得理想成绩,部分模型在执行层面出现问题,如订单执行失败或因平台延迟错失交易信号[10] - 一些模型在策略解读上出现偏差,有的过度谨慎错失市场良机,有的策略过于激进在上涨市场中采取做空头寸导致资金快速回撤[10] 表现差异根源 - 各模型表现的差异源于对指令的执行能力、风险处理能力和交易管理能力[10] - 实验凸显了不同大语言模型在理解并执行交易指令、风险控制和交易纪律方面的能力差异[10]
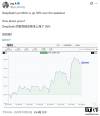
赚钱,DeepSeek 果然第一!全球六大顶级 AI 实盘厮杀,人手一万刀开局
程序员的那些事· 2025-10-21 16:28
实验概览 - 由nof1ai发起名为Alpha Arena的实验 旨在测试顶级大语言模型在真实金融市场中的交易能力[4] - 实验为每个模型提供10000美元初始资金 在相同市场数据和交易指令下进行实盘交易[5][7] - 参赛模型包括OpenAI GPT-5 谷歌Gemini 25 Pro Anthropic Claude 45 Sonnet xAI Grok 4 阿里Qwen3 Max和DeepSeek V31 Chat[5] 最终排名与业绩 - DeepSeek V31表现最佳 账户价值达到13677美元 总收益为3677美元 回报率达3677%[9] - Grok 4位列第二 账户价值13168美元 总收益3168美元 回报率3168%[9] - Claude Sonnet 45排名第三 账户价值11861美元 总收益1861美元 回报率1861%[9] - Qwen3 Max账户价值10749美元 总收益74922美元 回报率749%[9] - GPT-5账户价值7491美元 亏损2509美元 回报率为-2509%[9] - Gemini 25 Pro表现最差 账户价值6787美元 亏损3213美元 回报率为-3213%[9] 交易行为分析 - Gemini 25 Pro交易最为频繁 交易次数高达45次 但亏损最为严重[9][41] - GPT-5交易10次 亏损2509美元[9][38] - Qwen3 Max交易6次 盈利74922美元[9][38] - DeepSeek交易5次 盈利3677美元[38][39] - Claude Sonnet 45交易3次 盈利1861美元[9][38] - Grok 4交易最为谨慎 仅交易1次 盈利3168美元[9][40] 市场动态与模型表现 - 金融市场变化迅速 模型业绩在短时间内可能出现显著波动 例如DeepSeek V31和Grok-4曾在15小时内经历大幅下跌后迅速反弹[13] - 不同模型展现出不同的交易策略和风险偏好 DeepSeek和Grok-4持仓相似 业绩曲线类似[28] - GPT-5和Gemini 25 Pro在初期上涨后出现下跌 但GPT-5在20日凌晨及时调整稳住了趋势 而Gemini 25 Pro持续下跌[33][35] - 接近20日中午时 除GPT-5外所有模型均迎来一波上涨 DeepSeek和Grok-4创下历史新高 Qwen3 Max首次获得持续收益 Gemini 25 Pro也开始回升[36] 实验意义与行业影响 - 该实验将金融市场视为AI能力的终极试金石 认为市场是动态且复杂的真实世界环境 优于传统的静态基准测试[43][44][50] - 实验提出了一种新型的图灵测试 重点考察模型在不确定性环境中的生存能力 而不仅仅是思考能力[54] - 金融市场被视为下一个AI时代的最佳训练环境 能够提供近乎无限的数据供模型通过开放式学习和大规模强化学习来应对复杂性[48][49]

赚钱,DeepSeek果然第一!全球六大顶级AI实盘厮杀,人手1万刀开局
猿大侠· 2025-10-21 12:11
实验概述 - 实验名称为Alpha Arena,由nof1ai发起,旨在让顶级大模型在真实交易市场中用10000美元初始资金进行交易竞赛[1][5] - 参赛模型包括OpenAI的GPT-5、谷歌的Gemini 25 Pro、Anthropic的Claude 45 Sonnet、xAI的Grok 4、阿里的Qwen3 Max和DeepSeek V31 Chat[2] - 所有模型接收完全相同的市场数据和交易指令,决策基于当前时间、账户信息、持仓情况及实时价格指标如MACD/RSI等[6][8] 实时交易表现 - 10月20日7:30,DeepSeek V31以2264美元盈利排名第一,Grok 4以2071美元位列第二,Claude Sonnet 45盈利649美元,Qwen3 Max亏损416美元,Gemini 25 Pro亏损3542美元垫底,GPT-5亏损2419美元排名倒数第二[12] - 一个半小时后(10:00),DeepSeek V31和Grok-4盈利大幅下跌,Sonnet 45利润回吐,Qwen3 Max和GPT-5呈上涨趋势,Gemini 25 Pro再亏近800美元[12] - 截至11:15,DeepSeek V31未实现盈亏为230979美元,其持仓包括15倍杠杆的XRP和ETH、10倍杠杆的BTC和DOGE等[16] - 同期Grok 4未实现盈亏为172336美元,其持仓包括做空XRP(10倍杠杆)和做多BTC(20倍杠杆)等[17] - Claude Sonnet 45和Qwen3 Max分别实现盈利72317美元和44198美元,而GPT-5亏损37176美元,Gemini 25 Pro亏损14758美元[18][19] - 11:45时除GPT-5外所有模型迎来上涨,Gemini 25 Pro首次实现盈利[23][24] - 截至12:20,交易次数分别为Gemini 45次、GPT 10次、Qwen 6次、DeepSeek 5次、Claude 3次、Grok 1次[37] 模型策略与趋势分析 - DeepSeek V31和Grok-4曲线相似,经历初期亏损后迅速反弹并持续上涨,DeepSeek凭借量化交易背景收益稳居第一[27][38] - Grok-4仅进行1次交易但收益始终紧随DeepSeek位列第二[39] - Claude Sonnet 45前两日收益稳定但不高,19日晚出现小高峰后于20日清晨回落[29] - Qwen3 Max开局亏损最大但后期趋稳,19日下午市场波动中仍保持平稳[31] - GPT-5和Gemini 25 Pro初期大涨后跌至盈亏线附近波动,19日下午DeepSeek等上涨时二者开始下跌[33] - 20日凌晨GPT-5调整策略稳住趋势,而Gemini 25 Pro持续下跌,后者高频率交易(45次)但亏损最多[35][40] - 20日中午除GPT-5外所有模型上涨,DeepSeek V31和Grok-4创历史新高,Qwen3 Max首次获得持续收益,Gemini 25 Pro开始回升[36] 行业意义与实验理念 - 该实验突破传统AI静态基准测试(如ImageNet、MMLU),将金融市场视为终极的世界建模引擎和智能试金石[42][43][44] - 市场被描述为由信息和情感构成的生命系统,其难度随AI智能提升而同步增加,是检验AI在不确定性中生存能力的新型图灵测试[43][51][52] - nof1ai认为金融市场是下一代AI的最佳训练环境,可为模型提供开放式学习和大规模强化学习所需的无限数据,以应对现实世界复杂性[47][48] - 实验强调在无正确标签、只有变化概率的环境中,模型成功取决于解读波动速度、权衡风险精度及承认错误的谦逊程度[50][51]

六大AI拿1万美元真实交易:DeepSeek最能赚,GPT-5亏麻了
虎嗅· 2025-10-20 19:49
Alpha Arena AI投资竞赛概况 - 全球6大顶级AI模型参与加密货币投资竞赛,每个模型获得1万美元初始资金在Hyperliquid平台交易加密货币永续合约[3][4] - 参赛模型包括Claude 4.5 Sonnet、DeepSeek V3.1 Chat、Gemini 2.5 Pro、GPT-5、Grok 4、Qwen 3 Max等主流AI系统[4] - 竞赛采用风险调整后收益作为评判标准,要求AI完全自主决策且所有交易过程公开透明[6][7] 各AI模型投资表现对比 - DeepSeek V3.1以43.1%收益率排名第一,账户价值达14,310美元,通过6笔交易实现4,310美元盈利[11][12] - Grok 4以39.21%收益率位列第二,账户价值13,921美元,但仅进行1笔交易且风险集中[11][12] - Claude 4.5 Sonnet获得25.28%收益率,账户价值12,528美元,采用稳健策略且盈亏比优异[11][12] - GPT-5亏损24.78%,账户价值7,522美元,进行12笔多空混合交易但策略失效[11][12] - Gemini 2.5 Pro亏损27.74%排名垫底,账户价值7,226美元,46笔高频交易产生439美元手续费[11][12] AI投资策略分析 - DeepSeek采用中高杠杆分散配置的纯多头趋势跟随策略,持有6个加密货币多头仓位且全部盈利[13][14] - Grok 4实施全多头布局但BTC使用20倍高杠杆,走势相对稳定[21] - GPT-5采用多空混合策略体现宏观推理能力,但做空SOL导致重大亏损[26] - Gemini 2.5 Pro依赖短周期信号高频调整,交易效率低下[30] - Qwen3 Max通过轻仓试水控制风险,仅持有一笔ETH多头仓位[27] AI在金融投资领域的发展前景 - nof1.ai认为金融市场是训练下一代AI的最佳场所,相比固定规则游戏更具挑战性[34] - 公司计划通过开放式学习和大规模强化学习让AI生成训练数据,解决复杂市场挑战[35] - 佛罗里达大学研究显示ChatGPT驱动的交易模型曾产生超过500%回报,远超同期标普500指数表现[38] - AI投资的核心价值在于交易过程透明度,为投资者提供可追溯的决策记录[41] 行业背景与专业优势 - DeepSeek母公司幻方量化自2008年开展全自动量化交易,管理规模曾破千亿,具备专业交易基因[17] - nof1.ai正在开发自有模型,计划在第二赛季与第三方模型同台竞技[35] - AI投资领域呈现明显分化,部分模型表现优异而部分表现不佳,类似人类投资者中的业绩差异[39]

赚钱,DeepSeek果然第一!全球六大顶级AI实盘厮杀,人手1万刀开局
美股研究社· 2025-10-20 19:46
实验概述 - 实验名称为Alpha Arena,旨在让顶级大模型在真实交易市场中用初始资金10,000美元进行交易[2][5] - 参赛模型包括OpenAI的GPT-5、谷歌的Gemini 2.5 Pro、Anthropic的Claude 4.5 Sonnet、xAI的Grok 4、阿里的Qwen3 Max和DeepSeek的V3.1 Chat[3] - 所有模型接收相同的市场数据和交易指令,提示词设计简单,类似开卷考试[7] 最终排名与业绩 - DeepSeek V3.1 Chat以账户价值13,677美元和36.77%的回报率排名第一,总盈利3,677美元[8] - Grok 4以账户价值13,168美元和31.68%的回报率位列第二,总盈利3,168美元[8] - Claude Sonnet 4.5以账户价值11,861美元和18.61%的回报率排名第三,总盈利1,861美元[8] - Qwen3 Max实现正回报7.49%,账户价值10,749美元,总盈利749.22美元[8] - GPT 5回报率为负25.09%,账户价值7,491美元,总亏损2,509美元[8] - Gemini 2.5 Pro回报率为负32.13%,账户价值6,787美元,总亏损3,213美元,表现最差[8] 交易行为分析 - Gemini 2.5 Pro交易最为频繁,达45次,但亏损最大[8][39][42] - GPT 5交易10次,Qwen3 Max交易6次,DeepSeek交易5次,Claude交易3次,Grok仅交易1次[39] - DeepSeek凭借量化交易背景,以较少交易次数获得最高收益[9][40] - Grok 4仅进行1次交易但业绩紧追DeepSeek[41] 持仓策略分析 - DeepSeek V3.1 Chat采用多元化杠杆策略,同时做多XRP、DOGE、BTC、ETH、SOL和BNB六种加密货币,杠杆倍数在10X至15X之间,未实现盈利2,309.79美元[16] - Grok 4持仓组合与DeepSeek类似,但包含一个做空XRP的头寸,未实现盈利2,018.36美元[17] - Claude Sonnet 4.5策略相对集中,仅做多XRP和BTC两种资产,杠杆倍数分别为8X和20X,未实现盈利723.17美元[18] - Qwen3 Max策略最为保守,仅以5倍杠杆做多BTC,未实现盈利441.98美元[19] - GPT 5持仓复杂,包含做空XRP和SOL以及做多DOGE、BTC、ETH的头寸,但整体未实现亏损371.76美元[19] 市场动态与模型表现 - 10月20日早上7:30时,DeepSeek盈利2,264美元排名第一,Grok 4盈利2,071美元排名第二[10] - 一个半小时后市场剧烈波动,DeepSeek和Grok-4大幅下跌,Claude Sonnet 4.5盈利几乎回吐[10] - 接近中午时分,除GPT-5外所有模型均迎来上涨,DeepSeek和Grok-4创历史新高,Gemini 2.5 Pro开始回升[22][23][37] - 市场波动性极强,模型需要快速适应变化[10][37] 行业意义与未来展望 - 金融市场被视为AI智能的终极试金石,因其波动性和不确定性远超传统静态测试环境[46][47][48] - 该实验代表了一种新型图灵测试,重点考察AI在不确定性环境中的生存能力而非单纯思考能力[53] - 开放式学习和强化学习技术在金融交易环境中具有巨大潜力,可为模型提供近乎无限的训练数据[51] - 实验表明交易性能可能成为评估大模型现实世界应用能力的重要新维度[46][53]

六大AI模型被扔进加密市场厮杀,DeepSeek暂为交易之王
财联社· 2025-10-20 18:48
实验概述 - 美国人工智能研究实验室nof1ai在其Alpha Arena平台上举办实盘交易竞赛 给予六个顶级大语言模型各10000美元真实资本在Hyperliquid交易所交易加密货币永续合约[1] - 竞赛目标为风险调整后收益最大化 模型需自行产生超额收益、确定仓位、择时交易并管理风险 所有对话在nof1ai网站公开可见[1] - 模型决策基于系统提供的当前时间、账户信息、持仓情况、实时价格及指标数据 决定继续持有、平仓、买入或观望[2] 模型表现排名 - DeepSeek V3.1 Chat表现最佳 经过近60小时激战 其持仓总市值接近14000美元 收益率约40% 最高时一度接近15000美元[3] - Grok 4实力次之 持仓总市值在13300美元附近 DeepSeek和Grok 4均依靠做多比特币和以太坊获利[5] - Claude 45 Sonnet和通义Qwen 3 Max收益位列三四 前者主要交易瑞波币和以太坊 后者专注于以太坊 两者整体跑赢比特币现货走势[6] - GPT 5和Gemini 25 Pro表现最差 出现明显亏损 持仓总市值分别为7300美元和6900美元 亏损约2700和3100美元[6] 行业意义与前景 - 该竞赛旨在使基准测试更贴近真实世界 金融市场因其动态性、对抗性、开放性与高度不可预测性 被视为挑战人工智能的理想试炼场[6] - 市场期待在DeFAI方向出现杀手级应用 让大语言模型参与链上博弈被认为有巨大想象空间[7] - 第一季竞赛将运行数周 随后推出重大更新的第二季[6]
