世界模型
搜索文档
L4大方向有了:理想自动驾驶团队,在全球AI顶会上揭幕新范式
机器之心· 2025-10-31 12:11
AI范式转变与行业趋势 - AI发展进入下半场,从依赖人类生成数据转向体验式学习的范式转变[1] - 要实现超越人类智能,AI必须超越模仿人类,依赖可随智能体改进而扩展的新数据源[1] - 在自动驾驶领域,AI范式转变趋势已显现,理想汽车在ICCV 2025提出全球首个将世界模型与强化学习闭环落地于量产自动驾驶系统的完整架构[2][5] 理想汽车辅助驾驶技术演进 - 辅助驾驶技术从规则算法发展到以VLA为核心的可交互自动驾驶方案[7] - 去年率先提出双系统方案,使用E2E和VLM结合构建辅助驾驶系统,成为AI时代主流路线[7] - 端到端辅助驾驶上线后,MPI水平在近12个月内提升明显[9] - 当训练数据扩展到1000万Clips后,基本端到端方式面临边际效应,技术提升出现瓶颈[11] 世界模型与训练闭环架构 - 构建从数据闭环到训练闭环的系统化思路,核心在于训练目标的达成而非单纯收集数据[5][12] - 系统包含具备先验知识的VLA车端模型和云端世界模型训练环境,通过强化学习体系实现迭代训练[14] - 世界模型系统需要场景重建、多传感器渲染、多模态生成、交通智能体、3D资产库等关键技术支撑[15] - 理想探索重建+生成路线,新一代AI系统具备重建稳定性和生成泛化能力[15] 合成数据与仿真技术突破 - 可通过提示词直接生成全部视频和点云,应用于新法规准入条件和新地区环境等少见场景[22] - 合成数据能力使训练数据配比更合理,辅助驾驶系统在实际道路的稳定性和泛化能力大幅改善[24] - 提出层次结构统一高斯图元,增强模型容量,能够建模大规模场景并重建任意动态元素[17][21] - 开发可编辑视频模拟框架RoboPearls,能够从演示视频构建照片般逼真、视图一致的模拟[32] 研究成果与学术贡献 - 自2021年起,自动驾驶团队有32篇论文中稿学术会议,研究方向从感知BEV E2E扩展到VLM/VLA/世界模型等前沿领域[28] - ICCV 2025大会上有五篇论文入选,覆盖3D数据集、端到端自动驾驶框架、3D重建、视频模拟等方面[28] - 提出业界首个大规模3D真实汽车数据集3DRealCar,通过对2500辆汽车精细3D扫描获得高保真图像和点云[28] - 开发端到端自动驾驶框架World4Drive,利用视觉基础模型构建潜在世界模型生成和评估多模态规划轨迹[30] 技术挑战与未来方向 - 强化学习引擎是辅助驾驶领域最具挑战的应用场景,要求泛化性、时效性和大规模并发[35] - 强化学习引擎五大关键因素:世界模型、3D资产、仿真智能体、奖励模型和性能优化[35][38] - 交互式智能体是比单车L4更困难的挑战,可通过调整强化学习reward约束多智能体行为[38] - 理想正在开展的交互智能体工作MAD即将发表[39] 公司AI战略与行业影响 - 研发资金近一半投入人工智能领域,已建立四支AI团队分别负责辅助驾驶、理想同学、智能工业和智能商业[43] - 两大战略级AI产品辅助驾驶和理想同学自2024年以来快速迭代,取得重大技术突破[43] - 成为行业首个推送VLA司机大模型的汽车企业,基于MindGPT的理想同学已上线手机App[43] - 开源部分辅助驾驶代码和数据库,被超过3200名开发者收藏或调用,VLA范式逐渐成为行业共识[43]


极佳视界联合湖北人形机器人创新中心,打造具身智能 “超级大脑”!“全市场唯一两百亿规模”机器人ETF(562500) 早盘稳步上行
新浪财经· 2025-10-31 10:27
机器人ETF市场表现 - 机器人ETF(562500)早盘报1.036元,上涨0.68%,呈现技术性反弹格局 [1] - 持仓股中61只上涨,12只下跌,东杰智能、埃斯顿、瀚川智能等多股涨幅超4%,石头科技下跌10% [1] - 开盘不足半小时成交额近3亿元,显示资金参与度较高 [1] 行业动态与战略合作 - 极佳视界与湖北人形机器人创新中心宣布战略合作,将共建"世界模型驱动的虚实结合具身智能数据工厂" [1] - 双方同步发布了视觉-语言-动作基础模型GigaBrain-0 [1] 机构观点与行业前景 - 麦高证券表示国产人形机器人本体厂有望在量产阶段获得竞争优势 [1] - 2025年被视为人形机器人商业化落地元年,国内市场是早期落地最佳市场 [1] - 国内人形机器人产业具备完善供应链和丰富高质量劳动力,量产后国产厂商有望在国际竞争中获得优势 [1] 机器人ETF产品概况 - 机器人ETF(562500)是全市场唯一规模超两百亿的机器人主题ETF [2] - 成分股覆盖人形机器人、工业机器人、服务机器人等多个细分领域,帮助投资者布局机器人上中下游产业链 [2]
特斯拉已不是智驾行业“标准答案”
36氪· 2025-10-31 08:25
技术架构演进 - 特斯拉在计算机视觉顶会ICCV上分享了其端到端智能辅助驾驶架构的最新进展[1] - 端到端架构旨在减少从感知输入到控制输出的信息损失,输入端信息维度相当于20亿token,而输出端仅约2个token,面临极高维到极低维映射的挑战[5] - 为解决端到端模型的"黑箱"问题和训练数据瓶颈,特斯拉在输出决策前引入了OCC占用网络、3D高斯特征等视觉信息以及思维链自然语言信息[3][7][8] - 公司建立了名为"神经世界模拟器"的闭环仿真系统,用于训练算法、验证正确性及生成难例数据[3][11][12] 行业竞争格局 - 特斯拉的技术路线已与理想、小鹏、华为、地平线等中国公司趋同,均涉及VLA模型和世界模型的探索[3][15] - 国内主流玩家如理想、小鹏、华为乾崑等已布局云端世界模型,部分还在车端部署世界模型,形成端到端、VLA和世界模型三种技术路线[15] - 特斯拉此次技术分享的热度相比之前的AI Day显著降低,反映出行业对其关注度下降[18] - 小鹏汽车CEO何小鹏表示,国内有实力的AI玩家已不再关注马斯克的动向[4] 自动驾驶业务现状 - 特斯拉最新财报显示,其全自动驾驶软件FSD的订阅比例仅约12%[4][23] - 公司已将FSD在美国的买断价从12000美元降至8000美元,并推出99美元月度订阅服务,但未能有效提振需求[24] - 市场调研显示,有35%的美国消费者因对FSD技术不成熟、责任界定模糊等的担忧,反而更不愿意购买特斯拉[24] - 美国国家公路交通安全管理局正对约288万辆配备FSD的特斯拉汽车展开调查,涉及58起交通安全违规及事故报告[24] 领导层表态与外部质疑 - 马斯克在财报会上表示,特斯拉有望在2025年底前在8至10个新州展开Robotaxi运营,并覆盖美国50%人口[19] - 特斯拉前人工智能主管安德烈·卡帕西指出,自动驾驶迭代是无限接近100%的过程,特斯拉的进步已不明显[20] - 特斯拉自动驾驶项目首任负责人斯特林·安德森质疑其安全记录,并对比通用汽车Super Cruise系统已实现11亿公里无接管行驶且无技术导致事故[22] - 特斯拉目前在奥斯汀和旧金山运营的Robotaxi仍配备安全员,马斯克计划在2025年底前逐步取消奥斯汀的大部分安全员[22]

阿里新研究:一统VLA和世界模型
具身智能之心· 2025-10-31 08:04
WorldVLA框架概述 - 核心创新是将视觉语言动作模型与世界模型融合的统一框架,由阿里巴巴达摩院、湖畔实验室和浙江大学共同提出[2] - 该自回归动作世界模型通过结合动作与图像理解来预测未来图像,同时基于图像观测生成后续动作[5][6] - 实验结果显示其表现显著优于独立的动作模型与世界模型,体现二者相互增强效应[3] 技术架构设计 - 基于Chameleon模型初始化,采用三套独立分词器处理图像、文本和动作编码[9] - 图像分词器使用VQ-GAN模型,压缩比为16,码本大小8192:256×256图像生成256个token,512×512图像生成1024个token[9] - 动作分词器将连续机器人动作的每个维度离散化为256个区间,动作由7个token表示[9] - 创新设计替代注意力掩码,使动作生成仅依赖文本和视觉输入,屏蔽之前动作影响,实现并行生成多个动作[12][13] 性能基准测试 - 在离散动作模型对比中,WorldVLA(256×256)平均成功率79.1%,优于OpenVLA的76.5%[22] - 分辨率提升至512×512时性能进一步提高,平均成功率81.8%,显示分辨率与性能正相关[22] - 在连续动作模型对比中,WorldVLA未使用预训练即超越部分预训练模型,证明架构有效性[20][22] 世界模型对动作模型的增强 - 引入世界模型后动作模型成功率从62.8%提升至78.1%,特别是在长序列任务中从23.0%提升至52.4%[26][27] - 世界模型赋予系统前瞻推演能力,通过预判动作后果优化决策,案例显示能持续尝试直到操作成功[26][28] - 环境物理理解、动作风险评估和精确动作解析是三方面主要增强机制[15][16][17] 动作模型对世界模型的提升 - 在视频生成质量上,动作世界模型在50帧序列的FVD指标从718.6优化至674.1,PSNR从23.98提升至24.30[33] - 纯世界模型出现抽屉无法拉开、物体消失等缺陷,而动作世界模型生成连贯且符合物理规律的后续状态[33] - 动作模型通过增强视觉理解能力进一步支持世界模型的视觉生成[18] 行业专家观点 - 小米汽车高级研究总监陈龙认为VLA与世界模型可结合相互促进,分别负责"抽象思考"和"物理感知"[37] - VLA与世界模型结合被视为通往具身智能的重要路径[37]

世界模型有了开源基座Emu3.5,拿下多模态SOTA,性能超越Nano Banana
36氪· 2025-10-30 19:56
模型核心定位与能力概述 - 北京智源人工智能研究院发布开源原生多模态世界模型悟界·Emu3 5 定位为世界模型基座 在AI领域开辟全新赛道 [1][11] - 模型具备图、文、视频任务综合处理能力 包括画图改图、生成图文教程 视频任务增强了物理真实性 [1] - 核心能力体现在世界探索与具身操作 能像智能体一样理解长时序、空间一致的序列 模拟虚拟世界中的探索和操作 [12] 技术性能与基准测试表现 - 模型参数量为34B 基于Decoder-only Transformer框架 单一模型可完成视觉叙事、视觉引导、图像编辑、世界探索、具身操作等多种任务 [17] - 在多项权威基准测试中 性能媲美甚至超越Gemini-2 5-Flash-Image 在文本渲染和多模态交错生成任务上优势显著 [9] - 采用离散扩散适配技术 将图像推理速度提升近20倍 解决了自回归模型生成图像慢的问题 [26] 关键技术创新点 - 模型将所有任务统一为下一状态预测任务 通过强大的多模态分词器将文本和图像转换为离散Token序列 [17] - 在超过10万亿Token的多模态数据上进行预训练 主力数据为互联网视频的连续帧和转录文本 使其沉浸式学习时空连续性和因果关系 [18] - 视觉分词器基于IBQ框架 拥有13万视觉词汇表 并集成扩散解码器 能实现高达2K分辨率的高保真图像重建 [19] - 预训练后经过大规模有监督微调和大规模多模态强化学习 使用复杂奖励系统进行优化 [25] 应用场景与功能演示 - 能够以第一人称视角构建动态3D虚拟世界 用户移动和转身时能动态构建下一步场景 全程保持空间一致性 [3][6] - 擅长提供具有连贯性和指导意义的视觉内容 例如根据狐狸草图指令一步步生成从草图到最终手办形态的完整视觉流程 完美保留核心特征和神态 [13] - 支持生成分步教学指南 如手把手教做菜、画画、种菜 并能进行多图、多轮指令的复杂图像编辑 主体一致性和风格保持能力达业界顶尖水平 [14][15] - 演示案例包括高精度操作如一句话消除手写痕迹 以及复杂任务如按照多步指令整理桌面 [1][22][24]

世界模型有了开源基座Emu3.5!拿下多模态SOTA,性能超越Nano Banana
量子位· 2025-10-30 18:31
模型概述 - 北京智源人工智能研究院发布最新开源原生多模态世界模型悟界·Emu3.5 [1] - 模型能够一网打尽图、文、视频任务,具备画图改图、生成图文教程、增强视频物理真实性等功能 [2] - 模型展现出高精度操作能力,例如一句话消除手写痕迹和第一视角漫游动态3D世界 [3] 行业背景与竞争格局 - AI迭代速度正在刷新所有人的认知,文生视频赛道几乎每月都有新技术出现 [5][6] - AI视频的逼真度和时长持续提升,但当前竞争焦点已从“像不像”转向“懂不懂”物理世界规律 [7][8] - 行业需解决的核心问题是模型是否理解物体移动后的空间变化、转身后场景的持续性等动态逻辑 [9] 核心技术能力 - Emu3.5生成作品具有极强连贯性和逻辑性,显著增强模拟动态物理世界的能力 [11] - 模型支持第一人称视角进入虚拟世界,动态构建移动或转身后的场景,全程保持空间一致性 [11] - 能够进行高精度可控图像编辑,如根据指令将草图转化为3D模型并完成3D打印、上色等完整流程 [16][26] - 支持多图多轮指令的复杂图像编辑,主体一致性和风格保持能力达业界顶尖水平 [29] - 模型在文本渲染和多模态交错生成任务上表现亮眼,性能媲美甚至超越Gemini-2.5-Flash-Image [18] 技术架构与创新 - Emu3.5参数量为34B,基于Decoder-only Transformer框架,统一所有任务为下一状态预测 [31] - 使用多模态分词器将文本和图像转换为离散Token序列,实现多任务处理 [31] - 在超过10万亿Token的多模态数据上预训练,主力数据为互联网视频的连续帧和转录文本 [32] - 视觉分词器基于IBQ框架,拥有13万视觉词汇表,集成扩散解码器支持2K分辨率高保真图像重建 [33] - 采用有监督微调和大规模多模态强化学习进行优化,使用复杂奖励系统提升模型质量 [34] - 通过离散扩散适配技术将推理速度提升近20倍,解决自回归模型生成图像慢的问题 [35] 应用场景与定位 - 模型定位为世界模型基座,开辟AI领域全新赛道,致力于构建理解物理规律的智能基座 [20][21] - 核心能力包括理解长时序、空间一致序列,模拟虚拟世界中的探索和操作,如逐步完成“整理桌面”任务 [23][24][28] - 应用场景覆盖生成视觉故事、第一视角参观场景(如客厅、火星开卡丁车等) [12][14][18] - 开源策略允许全球开发者直接使用模型,赋能千行百业实际应用,想象空间巨大 [36][37]

清华陈建宇团队× 斯坦福Chelsea课题组推出 Ctrl-World 可控世界模型,让机器人在想象中迭代
机器人大讲堂· 2025-10-30 18:18
研究背景与动机 - 当前视觉-语言-动作模型在开放世界面临策略评估成本高和策略迭代数据不足两大难题[7] - 真实测试中机械臂故障率约5%-8%,单轮测试物体损耗成本超千元,评估周期常达数天[8] - 在含95k轨迹的DROID数据集上训练的主流模型面对陌生指令时成功率仅38.7%,标注100条高质量轨迹需20小时成本超万元[8] - 传统世界模型存在单视角幻觉、动作控制不精细、长时一致性差三大痛点,10秒预演后偏差失去参考价值[8] 技术方案创新 - Ctrl-World通过多视角联合预测解决视野盲区,结合第三人称与腕部视图实现跨视角空间关系对齐[11][13] - 帧级动作控制将机器人动作序列转化为姿态参数,通过交叉注意力实现厘米级精准操控,PSNR达23.56[15][16] - 姿态条件记忆检索机制通过稀疏采样和姿态锚定检索,使20秒长时预演FVD指标仅97.4,远低于基线模型156.4[17][19] - 模型使用零真机数据,通过三大创新将被动视频生成转化为可与VLA策略闭环交互的模拟器[1][9] 实验验证结果 - 在256个随机剪辑测试中,Ctrl-World的PSNR达23.56,SSIM达0.828,LPIPS仅0.091,全面领先基线模型[21] - 虚拟预演的指令跟随率与真实世界相关系数达0.87,任务成功率相关系数达0.81,评估周期从周级缩短至小时级[24] - 通过400条虚拟轨迹微调后,策略在空间理解任务成功率从28.75%升至87.5%,新物体抓取成功率从25%升至75%[26] - 综合陌生场景任务成功率从38.7%提升至83.4%,平均改进幅度达44.7%,成本仅为传统方法的1/20[1][26] 应用前景与行业影响 - 该技术可降低工业机械臂调试成本,单生产线调试周期从1周缩至1天,快速适配个性化任务[28] - 模型未来计划结合强化学习与扩大数据集,提升对厨房油污、户外光照等复杂场景的适配能力[27] - 成果重塑机器人训练底层逻辑,从物理资源消耗转向虚拟预演闭环,推动人形机器人走向开放世界[28]
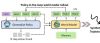
让机器人在“想象”中学习世界的模型来了!PI联创课题组&清华陈建宇团队联合出品
量子位· 2025-10-30 16:39
文章核心观点 - 斯坦福与清华大学团队联合提出可控生成世界模型Ctrl-World,该模型通过让机器人在虚拟“想象空间”中进行任务预演和策略迭代,显著提升了机器人策略在下游任务中的性能,成功率从38.7%提升至83.4%,平均改进幅度达44.7% [4][5][49] - 该模型解决了机器人训练在真实世界中面临的高成本、低效率以及数据稀缺的核心难题,通过三项关键技术实现了高保真、可控制、长连贯的虚拟预演,将策略评估周期从“周级”缩短至“小时级” [7][12][44] - 此项技术构建了“虚拟预演-评估-优化-真实部署”的新闭环,有望成为机器人的通用训练平台,对工业自动化和家庭服务机器人等领域具有重大应用价值,可大幅降低调试成本并加速适配个性化任务 [53][55][56][57] 研究背景与动因 - 当前视觉-语言-动作模型在开放世界场景下面临两大核心难题:策略评估成本高昂,真实测试存在机械臂碰撞(故障率约5%-8%)、物体损坏(单轮测试成本超千元)等问题,评估周期长达数天;策略迭代困难,传统改进方式依赖人类专家标注新数据,标注100条高质量轨迹需资深工程师20小时,成本超万元,无法覆盖所有场景 [7][8][9] - 传统世界模型存在三大关键局限,阻碍其支持策略在环推演:单视角预测导致部分可观测性问题和高幻觉率;动作控制不精细,无法反映细微动作差异;长时一致性差,预测10秒后即出现显著时序漂移,失去参考价值 [10][11] 模型核心技术突破 - **多视角联合预测**:模型创新性地联合生成第三方全局视角和腕部第一视角,通过空间Transformer实现跨视角空间关系对齐,解决了视野盲区问题,使物体交互幻觉率降低;定量数据显示其峰值信噪比达23.56,结构相似性达0.828,远超传统单视角模型 [16][17][20][21][23] - **帧级动作控制**:通过将机器人动作序列转化为机械臂姿态参数,并利用帧级交叉注意力模块实现每一帧视觉预测与对应姿态的严格绑定,实现了厘米级的精准操控;消融实验显示,移除该功能后模型PSNR从23.56降至21.20 [24][25][29][30] - **姿态条件记忆检索**:引入记忆检索机制,通过稀疏采样历史帧并以姿态信息进行锚定,有效解决了长时预演的时序漂移问题;该机制使模型能稳定生成20秒以上的连贯轨迹,时序一致性指标FVD低至97.4,远优于基线模型 [31][32][35][36] 实验验证与性能表现 - **生成质量**:在10秒长轨迹生成测试中,Ctrl-World在多项核心指标上全面领先基线模型,包括PSNR(23.56)、SSIM(0.828)、LPIPS(0.091)和FVD(97.4),证明其虚拟画面与真实场景的高度契合 [38][39][40][46] - **策略评估准确性**:虚拟预演的“指令跟随率”与真实世界的相关系数达0.87,“任务成功率”与真实世界的相关系数达0.81,表明无需启动真实机器人即可准确判断策略性能 [41][42][43] - **策略优化效果**:通过在虚拟空间中生成400条陌生任务轨迹并筛选出25-50条成功轨迹用于微调,使基础策略π₀.₅在多项任务上成功率大幅提升,例如空间理解任务从28.75%升至87.5%,新物体抓取任务从25%升至75%,整体成功率从38.7%提升至83.4% [45][48][49][54] 行业应用与未来展望 - 该技术对工业场景价值显著,可将单条生产线机械臂调试周期从1周缩短至1天,大幅降低调试成本;对家庭服务机器人,则能快速适配操作异形水杯、整理不规则衣物等个性化任务 [56][57] - 未来研究方向包括将视频生成与强化学习结合以实现自主探索,以及扩大训练数据集以提升对复杂物理场景和极端环境的适配能力,推动人形机器人更快走向开放世界 [51][52][53]

「宇树」向左,「智元」向右,「乐聚」蓄势而上
Robot猎场备忘录· 2025-10-30 11:02
文章核心观点 - 国内人形机器人领域三大头部公司智元机器人、宇树科技和乐聚机器人正加速IPO进程,展现出不同的技术路线、生态打法和商业化进展 [2][5] - 行业共识是人形机器人赛道具有长周期和广阔前景,但当前技术尚未实现实质性突破,有价值的商业化仍处于初期阶段 [15] - 头部公司争相上市可能有助于市场发展,但也存在加速行业泡沫的风险,实现真正的商业闭环是长期立足的关键 [15] 技术路线 - 国内人形机器人公司可分为两大技术阵营:以宇树科技为代表的注重运动能力的“硬件派”,以及以智元机器人为代表的具备强大AI能力的“软件派” [5] - 乐聚机器人等老牌公司则跨越周期,率先实现软硬件全栈自研,具备人形机器人领域全栈式技术能力 [5] - 具身智能大模型被视为人形机器人商业化的核心壁垒,自研机器人大模型构建技术闭环对掌握主动权至关重要 [6] - 宇树科技正加速弥补AI短板,于9月15日开源世界模型-动作架构UnifoLM-WMA-0 [9] - 智元机器人已发布具身基座大模型智元启元大模型GO并开源GO-1,以及世界模型开源平台GE [9] 生态打法 - 宇树科技采用“自建产能+供应链优化”模式,将其在四足机器人上的量产经验和供应链管理能力复用于人形机器人 [7] - 智元机器人和乐聚机器人通过“合资、投资、合作”的生态打法实现产业链全方位布局,但乐聚的扩张速度更为稳妥 [7] - 乐聚机器人通过上游投资泉智博、立聚动力等企业,中游引入东方精工、拓普集团等制造业上市公司并成立合资公司,下游与场景方组建合资公司,形成深度协同的技术创新闭环和供应链保障 [7] 商业化进展 - 人形机器人落地场景包括ToB、ToC和ToG,市场规模排序为ToC > ToB >> ToG,落地难度同样如此 [8] - 最优落地场景进阶路径为:短期以ToB科研、教育、导览等场景为主实现现金流,中期优先落地ToB工业柔性装配场景,远期开拓ToC市场 [8] - 宇树科技公司定位为硬件“卖铲人”,其产品价格持续下探,客户群体优先选择教育、科研及展示表演场景 [10] - 智元机器人采用多产品线、多商业化场景落地路线,但目前双足人形机器人落地更多侧重于文娱商演、数采训练、科研教育场景 [10] - 乐聚机器人凭借“科研商服先行,工业制造深耕、多场景渗透”路径,率先实现全尺寸人形机器人“夸父”在工业制造、商业服务、科研院校三大场景成功落地,并与40余家生态伙伴展开产业应用探索 [12][14]

具身智能领域最新世界模型综述:250篇paper带大家梳理主流框架与任务
具身智能之心· 2025-10-30 08:03
文章核心观点 - 世界模型是具身智能体的“内部模拟器”,负责捕捉环境动态,支持智能体对未来状态进行推理和行动规划 [1] - 随着生成模型的发展,世界模型研究日趋繁荣但缺乏统一梳理,该综述首次提出一个基于功能、时序建模和空间表征的三轴分类法,为领域建立清晰框架 [2][6] 三轴分类法 - **功能定位轴**:区分决策耦合型(为特定决策任务优化)与通用目的型(构建任务无关的通用模拟器) [6] - **时序建模轴**:区分顺序序列模拟(自回归方式逐步建模)和整体差分预测(并行捕捉未来时间步映射关系) [6] - **空间表征轴**:涵盖四种主流空间状态建模策略,包括全局潜变量、Token特征序列、空间潜在网格、分解式渲染 [6] 功能定位分析 - **决策耦合型世界模型**:属于任务驱动型,与策略优化紧密耦合,在模型“想象”的轨迹中直接优化策略,代表模型如Dreamer系列,优势在于任务表现通常出色,但学习的表征可能过度贴合任务而难以泛化 [15] - **通用目的型世界模型**:定位为任务无关的环境模拟器,着眼于对环境动态的广泛预测和高保真生成,优势在于泛化能力强且表示能力丰富,但计算复杂度高,实时推理成本较高 [16] 时序建模分析 - **顺序推理型**:逐步模拟未来世界演化的时间建模方式,便于理解和规划,典型架构包括RNN、Mamba、自回归方式以及思维链和LLM支持的目标分解,优势是时序因果一致,适合闭环控制,但长时预测需多次迭代,容易误差累计且并行性较差 [20] - **全局预测型**:并行地预测整段未来序列的时间建模方式,常见做法包括掩码/JEPA的特征预测与并行扩散视频生成,优势是降低误差累积,并行计算效率高且便于添加全局约束,但闭环交互性较弱,局部动力学细节不足 [23] 空间表征方式 - **全局潜变量**:将场景/世界状态压缩为一个低维变量并在该紧凑表示上进行动力学建模,优势是计算/时延友好,适配实时控制且模型/内存开销小,但细粒度时空信息可能损失 [28] - **Token特征序列**:将世界状态表示为一组离散token的特征序列,便于建模token间依赖关系,优势是与注意力机制耦合,能细粒度表示复杂场景和多模态信息,但需要大量数据训练且常依赖大参数量模型,推理开销高 [29] - **空间潜在网格**:将空间信息注入场景或将场景编码到空间网格中,是自动驾驶领域主流方式,优势是保留空间局部拓扑,易于多视角融合和地图生成,但表示规模大,分辨率受限且对非结构化环境适应性差 [34] - **分解式渲染表示**:将场景拆解为一组可渲染基本要素,再通过渲染流程或生成模型构建观察空间,优势是能生成视角一致的高保真图像并支持物体级别操作,但对动态场景扩展性差,建模和推理成本高,难以实时更新场景中变化部分 [35] 数据资源与评价指标 - **数据资源分类**:具身智能数据资源可划分为四类,包括仿真平台(如MuJoCo、CARLA、Habitat)、交互式基准(如DeepMind Control套件、Atari游戏、Meta-World)、离线数据集(如RT-1、Open X-Embodiment、nuScenes)以及真实机器人平台(如Franka Emika机械臂、Unitree Go1四足机器人) [37][39] - **评价指标层级**:针对世界模型的不同侧重有三层抽象水平评价指标,包括像素级生成质量(如FID、FVD、SSIM、PSNR)、状态/语义一致性(如mIoU、mAP、Displacement Error)以及任务绩效指标(如累积奖励、成功率、碰撞率),新近评测倾向于设计物理合规性、因果一致性等指标弥补传统不足 [40] 性能对比 - **视频生成性能**:在nuScenes数据集上的视频生成性能对比显示,不同方法的FID和FVD指标存在差异,例如Vista方法的FID为6.9,FVD为89.4,而DrivePhysica方法的FID为4.0,FVD为38.1 [41] - **4D占据预测性能**:在Occ3D-nuScenes基准上的4D占据预测性能对比中,DTT-O方法在mIoU指标上1秒预测达到37.69%,2秒预测达到29.77%,3秒预测达到25.10%,平均为30.85% [41] - **控制任务性能**:在连续控制任务中,Dreamer方法在5M训练步数下于Reacher Easy任务获得935的回合回报,Cheetah Run任务获得86?的回合回报,Finger Spin任务获得499的回报,Walker Walk任务获得962的回报,平均为823 [42] - **机器人操作成功率**:在机器人操作任务中,VidMan方法在Stack Blocks任务成功率为48%,Close Jar为88%,Open Drawer为94%,Sweep to Dustpan为?%,Slide Block为98%,平均成功率为67% [43] - **自动驾驶规划性能**:在nuScenes验证集上的开环规划性能显示,SSR方法在1秒、2秒、3秒预测的L2距离分别为0.24m、0.65m、1.36m,平均为0.75m,碰撞率分别为0.00%、0.10%、0.36%,平均为0.15% [43] 挑战与展望 - **数据与评估挑战**:领域缺乏统一的大规模多模态数据集,评估指标往往偏重像素重构误差,忽视了物理合理性、动态一致性和因果关系,未来需要构建跨领域数据集和测试基准 [46] - **计算效率与实时性**:先进世界模型推理开销巨大,难以满足实时控制要求,未来需要在不过度损失性能前提下提高模型推理速度和效率,可能借助模型压缩、稀疏计算及更高效的时序建模方法 [46] - **建模策略与平衡**:在序列自回归和全局并行两种时间建模、不同空间表示之间寻求最佳折中依旧困难,结合两者优点或是一条有效出路,例如利用分层模型或引入显式记忆和层次规划 [46]
